Show code cell source
MAKE_BOOK_FIGURES=True
import numpy as np
import scipy.stats as st
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib_inline
matplotlib_inline.backend_inline.set_matplotlib_formats('svg')
import seaborn as sns
sns.set_context("paper")
sns.set_style("ticks")
def set_book_style():
plt.style.use('seaborn-v0_8-white')
sns.set_style("ticks")
sns.set_palette("deep")
mpl.rcParams.update({
# Font settings
'font.family': 'serif', # For academic publishing
'font.size': 8, # As requested, 10pt font
'axes.labelsize': 8,
'axes.titlesize': 8,
'xtick.labelsize': 7, # Slightly smaller for better readability
'ytick.labelsize': 7,
'legend.fontsize': 7,
# Line and marker settings for consistency
'axes.linewidth': 0.5,
'grid.linewidth': 0.5,
'lines.linewidth': 1.0,
'lines.markersize': 4,
# Layout to prevent clipped labels
'figure.constrained_layout.use': True,
# Default DPI (will override when saving)
'figure.dpi': 600,
'savefig.dpi': 600,
# Despine - remove top and right spines
'axes.spines.top': False,
'axes.spines.right': False,
# Remove legend frame
'legend.frameon': False,
# Additional trim settings
'figure.autolayout': True, # Alternative to constrained_layout
'savefig.bbox': 'tight', # Trim when saving
'savefig.pad_inches': 0.1 # Small padding to ensure nothing gets cut off
})
def set_notebook_style():
plt.style.use('seaborn-v0_8-white')
sns.set_style("ticks")
sns.set_palette("deep")
mpl.rcParams.update({
# Font settings - using default sizes
'font.family': 'serif',
'axes.labelsize': 10,
'axes.titlesize': 10,
'xtick.labelsize': 9,
'ytick.labelsize': 9,
'legend.fontsize': 9,
# Line and marker settings
'axes.linewidth': 0.5,
'grid.linewidth': 0.5,
'lines.linewidth': 1.0,
'lines.markersize': 4,
# Layout settings
'figure.constrained_layout.use': True,
# Remove only top and right spines
'axes.spines.top': False,
'axes.spines.right': False,
# Remove legend frame
'legend.frameon': False,
# Additional settings
'figure.autolayout': True,
'savefig.bbox': 'tight',
'savefig.pad_inches': 0.1
})
def save_for_book(fig, filename, is_vector=True, **kwargs):
"""
Save a figure with book-optimized settings.
Parameters:
-----------
fig : matplotlib figure
The figure to save
filename : str
Filename without extension
is_vector : bool
If True, saves as vector at 1000 dpi. If False, saves as raster at 600 dpi.
**kwargs : dict
Additional kwargs to pass to savefig
"""
# Set appropriate DPI and format based on figure type
if is_vector:
dpi = 1000
ext = '.pdf'
else:
dpi = 600
ext = '.tif'
# Save the figure with book settings
fig.savefig(f"{filename}{ext}", dpi=dpi, **kwargs)
def make_full_width_fig():
return plt.subplots(figsize=(4.7, 2.9), constrained_layout=True)
def make_half_width_fig():
return plt.subplots(figsize=(2.35, 1.45), constrained_layout=True)
if MAKE_BOOK_FIGURES:
set_book_style()
else:
set_notebook_style()
make_full_width_fig = make_full_width_fig if MAKE_BOOK_FIGURES else lambda: plt.subplots()
make_half_width_fig = make_half_width_fig if MAKE_BOOK_FIGURES else lambda: plt.subplots()
Basics of Probability Theory#
Logical sentences#
A logical sentence is a statement about the world that can be true or false. Science makes such statements all the time. For example, “the circumference of the Earth is 40,075 km (plus or minus 1 km)” is a logical sentence. We will not go any deeper into the formal definition of logical sentences. But we will require that the set of logical sentences we are working with is consistent. That is, it does not contain contradictions.
We will denote logical sentences with capital letters: \(A\), \(B\), \(C\), etc. We form new logical sentences from old ones using the following logical connectives:
\(\text{not}\;A \equiv \neg A\): the logical sentence that is true when \(A\) is false and false when \(A\) is true.
\(A\;\text{and}\;B \equiv A, B \equiv AB\): the logical sentence that is true when \(A\) and \(B\) are true and false otherwise.
\(A\;\text{or}\;B \equiv A+B\): the logical sentence that is true when \(A\) or \(B\) are true and false otherwise.
Probability as a representation of our state of knowledge#
Let’s call \(I\) the logical sentence containing all information you have now. And I am talking about absolutely everything:
What your parents taught you,
What you learned in school, what you learned in college,
What your eyes see right now on some scientific instruments.
Now consider a logical sentence \(A\) that says something about the world. For example, \(A\) could be “The result of the next coin toss John performs will be heads.” Or anything. We are uncertain about \(A\). We do not know if it is true or false. We could use the information \( I \) to say something more about \( A \). Maybe we believe that it is more likely that \(A\) is true than false. Maybe the opposite.
Probability theory is about this problem. It gives us a number \(p(A|I)\). We read \(p(A|I)\) as “the probability that \(A\) is true given that we know \(I\).” It quantifies our degree of belief that \(A\) is true given that we know \(I\). We say that \(p(A|I)\) represents our knowledge about \(A\) given \(I\).
But what about frequencies?#
In introductory courses to probability or statistics, we usually learn that the probability of an event is the frequency with which it occurs in nature. This interpretation is valid if the event is something that indeed occurs repeatedly. However, it is pretty restrictive.
In particular, what can we say about an event that can happen only once? For example, what is the probability that life on Earth will end in a billion years? It is not possible to repeat this experiment. It is not even possible to observe its outcome. The frequency interpretation of probability is not applicable. However, we would like to use probability to quantify our degree of belief that life on Earth will end in a billion years. It makes intuitive sense that we can do this. We want to do this. Scientists and engineers think like this all the time.
But is our approach compatible with the frequency interpretation? It can be shown, see [Jaynes, 2003] for the proof, that our approach is indeed compatible with the frequency interpretation. That is, when events occur repeatedly, then the probabilities do become frequencies.
The common sense assumptions that give rise to the basic probability rules.#
Probability theory is nothing but common sense reduced to calculation. Pierre-Simon Laplace, Théorie analytique des probabilités (1814)
Consider the following three ingredients:
A: a logical sentence
B: another logical sentence
I: all the information we know
Now, let’s try to make a robot that can argue under uncertainty. It should be able to take logical sentences (such as \(A\) and \(B\) above) and argue about them using all its information. What sort of system should govern this robot? The following desiderata, see [Jaynes, 2003], seem reasonable:
Real numbers represent degrees of plausibility.
The system should have a qualitative correspondence to common sense.
The system should be consistent in the sense that:
If there are two ways to calculate a degree of plausibility, each way must lead to the same result.
The robot should take into account all evidence relevant to a question.
Equivalent plausibility assignments must represent equivalent states of knowledge.
Cox’s theorem shows that:
The desiderata are enough to derive the rules of probability theory.
Talking about probabilities#
We read \(p(A|BI)\) as:
the probability of \(A\) being true given that we know that \(B\) and \(I\) are true; or
the probability of \(A\) being true given that we know that \(B\) is true; or
the probability of \(A\) given \(B\).
Interpretation of probabilities#
The probability \(p(A|BI)\) is a number between 0 and 1, quantifying the degree of plausibility that \(A\) is true given \(B\) and \(I\). Specifically:
\(p(A|B,I) = 1\) when we are certain that \(A\) is true if \(B\) is true (and I).
\(p(A|B,I) = 0\) when we are certain that \(A\) is false if \(B\) is true (and \(I\)).
\(0< p(A|B,I) < 1\) when we are uncertain about \(A\) if \(B\) is true (and \(I\)).
\(p(A|B,I) = \frac{1}{2}\) when we are completely ignorant about \(A\) if \(B\) is true (and \(I\)).
The rules of probability#
Everything in probability theory derives from two rules. These are direct consequences of the desiderata and Cox’s theorem. They are:
The obvious rule:
The rule states that \(A\) or its negation must be true. We see why it is vitally important that you refrain from applying probability in a system that includes contradictions.
The product rule (or Bayes’ rule or Bayes’ theorem):
The rule states that the probability of \(A\) and \(B\) is the probability of \(A\) given that \(B\) is true times the probability that \(B\) is true. Even though the correspondence is not one-to-one, visualizing events using the Venn diagrams helps in understanding the product rule:
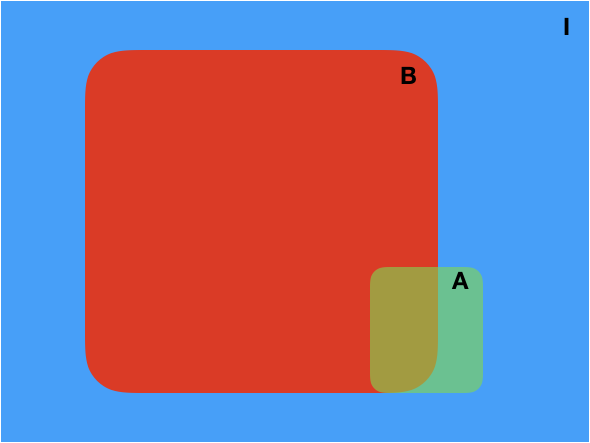
Fig. 2 Venn diagram.#
In this diagram:
\(p(A,B|I)\) corresponds to the brown area (normalized by the area of I).
\(p(B|I)\) is the area of \(B\) (normalized by the area of \(I\)).
\(p(A|BI)\) is the brown area (normalized by the area of \(B\)).
Understanding the product rule takes some time. But it is worth it, as it tells us how to update our knowledge as we gather new information. The product rule is the essence of scientific machine learning.
Example: Drawing balls from a box without replacement (1/3)#
Consider the following information \(I\):
We are given a box with ten balls, 6 of which are red and 4 of which are blue. The box is sufficiently mixed so that we don’t know which one we pick when we get a ball from it. We do not put a ball back when we take it out of the box.

Fig. 3 A box with balls.#
Now, let’s draw the first ball. Here is the graphical causal model up to this point:
Show code cell source
from graphviz import Digraph
gu1 = Digraph('Urn1')
gu1.node('I', label='Background information I', style='filled')
gu1.node('first', label='Result of 1st draw')
gu1.edge('I', 'first')
gu1.render('ch2.fig1', format='pdf')
gu1

Now, let’s say that we draw the first ball. Let \(B_1\) be the sentence:
The first ball we draw is blue.
What is the probability of \(B_1\)? Our intuition tells us to set:
What just did has a name. It is known as the principle of insufficient reason. We will learn more about it later.
We can now use the obvious rule to find the probability of drawing a red ball, i.e., of \(\neg B_1\). Of course, \(\neg B_1\) is just the sentence:
The first ball we draw is red.
So, let’s call it also \(R_1\). It is:
Now let’s do something else. Let’s say we observe the first draw and we want to calculate the probability of drawing a blue ball on the second draw. Consider the causal graph of the problem. We need to fill the node corresponding to the first draw with color:
Show code cell source
gu3 = Digraph('Urn3')
gu3.node('I', label='Background information I', style='filled')
gu3.node('first', label='Result of 1st draw', style='filled')
gu3.node('second', label='Result of 2nd draw')
gu3.edge('I', 'first')
gu3.edge('I', 'second')
gu3.edge('first', 'second')
gu3.render('ch2.fig2', format='pdf')
gu3

Consider the sentence \(R_2\):
The second ball we draw is red.
Suppose we know that \(B_1\) is true, i.e., the first ball we draw is blue. What is the probability of \(R_2\) given that \(B_1\) is true? We can use common sense to find this probability:
We had ten balls, six red and four blue.
Since \(B_1\) is true (the first ball was blue), we now have six red and three blue balls.
Therefore, the probability that we draw a red ball next is:
Similarly, we can find the probability that we draw a red ball in the second draw given that we drew a red ball in the first draw:
We had ten balls, six red and four blue.
Since \(R_1\) is true (the first ball is red), we now have five red and four blue balls.
Therefore, the probability that we draw a red ball next is:
Okay, let’s do something more challenging. Let’s consider a second draw without observing the result of the first draw. Here is the causal graph (notice that we do not shade the first draw):
Show code cell source
gu2 = Digraph('Urn2')
gu2.node('I', label='Background information I', style='filled')
gu2.node('first', label='Result of 1st draw')
gu2.node('second', label='Result of 2nd draw')
gu2.edge('I', 'first')
gu2.edge('I', 'second')
gu2.edge('first', 'second')
gu2.render('ch2.fig3', format='pdf')
gu2

Let’s find the probability that we will draw a blue ball in the first draw (A) and a red ball in the second draw (B). We have to use the product rule:
Other rules of probability theory#
All other rules of probability theory can be derived from the two basic rules. Here are some examples.
Extension of the obvious rule#
All other rules of probability theory can be derived from the two basic rules. Here are some examples.
Extension of the obvious rule#
For any two logical sentences \(A\) and \(B\) we have:
In words: the probability of \(A\) or \(B\) is the probability that A is true plus the probability that \(B\) is true minus the probability that both A and B are true. It is easy to understand the rule intuitively by looking at the Venn diagram.
The probability \(p(A+B|I)\) is the area of the union of A with B (normalized by I). This area is indeed the area of A (normalized by I) plus the area of B (normalized by I) minus the area of A and B (normalized by I), which was double-counted.
Here is the proof.
The sum rule#
The sum rule is the final rule we will consider in this lecture. It is one of the most important rules. You have to memorize it. It goes as follows.
Consider the sequence of logical sentences \(B_1,\dots,B_n\) such that:
One of them is true:
No two of them can be true at the same time:
Then, for any logical sentence \(A\), we have:
Again, this requires a bit of meditation. You take any logical sentence A and set of mutually exclusive but exhaustive possibilities \(B_1,\dots, B_n\), and you break down the probability of \(A\) in terms of the probabilities of the \(B_i\)’s. The Venn diagrams help to understand the situation:
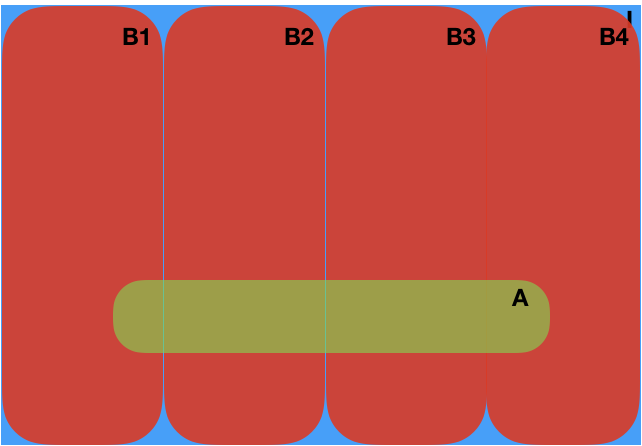
Fig. 4 Venn diagram demonstration of the sum rule.#
The sum rule can be trivially proved by induction using only the obvious rule and the product rule.
It is instructive to go through the proof once. :class: dropdown For \(n=2\) we have:
because
And then, assume that it holds for \(n\), you can easily show that it also holds for \(n+1\) completing the proof.
Example: Drawing balls from a box without replacement (2/3)#
Let us consider the probability of getting a red ball in the second draw without observing the first draw. We have two possibilities for the first draw. We got a blue ball (\(B_1\) is true) or a red ball (R_1 is true). In other words, \(B_1\) and \(R_1\) cover all possibilities and are mutually exclusive. We can use the sum rule:
Example: Drawing balls from a box without replacement (3/3)#
If you paid close attention, in all our examples, the conditioning we did followed the causal links. For instance, we wrote \(p(R_2|B_1 I)\) for the probability of getting a red ball in the second draw after observing the blue ball in the first draw. However, conditioning on stuff does not have to follow causal links. It is legitimate to ask what the probability of a blue ball is in the first draw, given that you have observed that the result of the second draw is a red ball. I visualize the situation in the following graph:
Show code cell source
gu4 = Digraph('Urn4')
gu4.node('reds', label='# red balls', style='filled')
gu4.node('blues', label='# blue balls', style='filled')
gu4.node('first', label='1st draw')
gu4.node('second', label='2nd draw', style='filled')
gu4.edge('reds', 'first')
gu4.edge('blues', 'first')
gu4.edge('first', 'second')
gu4.edge('reds', 'second')
gu4.edge('blues', 'second')
gu4.render('urn4_graph', format='png')
gu4

You can write down the mathematical expression \(p(B_1|R_2, I)\). It does not mean that \(R_2\) is causing \(B_1\). What happens here is that observing \(R_2\) changes your state of knowledge about \(B_1\). It is an example of information flowing in the reverse order of a causal link and a quintessential example of the inverse problem. Let’s solve it analytically:
The probability is greater than that of drawing a blue ball in the first place, \(p(B_1|I) = 0.4\). Does this make sense? Yes, it does! Here is what you should think:
You draw a ball without seeing it and put it in a box.
You draw the second ball, and you see that it is a red one.
This means you did not pick this red ball in the first draw.
So, it is as if, in the first draw, you had one less red to worry about, which increases the probability of a blue.
So, it is as if you had five red balls and four blue balls, giving you a probability of blue \(\frac{4}{9}\approx 0.44\).
It is amazing! It agrees perfectly with the prediction of the product rule. Recall that one of our desiderata is that if you compute something in two different ways, you should get the same result. You can rest assured that it is impossible to get the wrong answer as soon as you use the product rule, the sum rule, and logic.